Distributed Web of Care
Documentation: Ethics and Archiving the Web
The first public event of Distributed Web of Care was presented as a part of Rhizome’s Ethics & Archiving the Web conference at the New Museum, NYC, March 24, 2018. The workshop offered resources for getting started with the Distributed Web, and invited computer scientists and domain experts to host an open conversation on counter-narratives to the mainstream internet.

Taeyoon Choi
The first question that we would like to address: how can we define care in the context of the web? There are three kinds of networks that I drew in my painting.
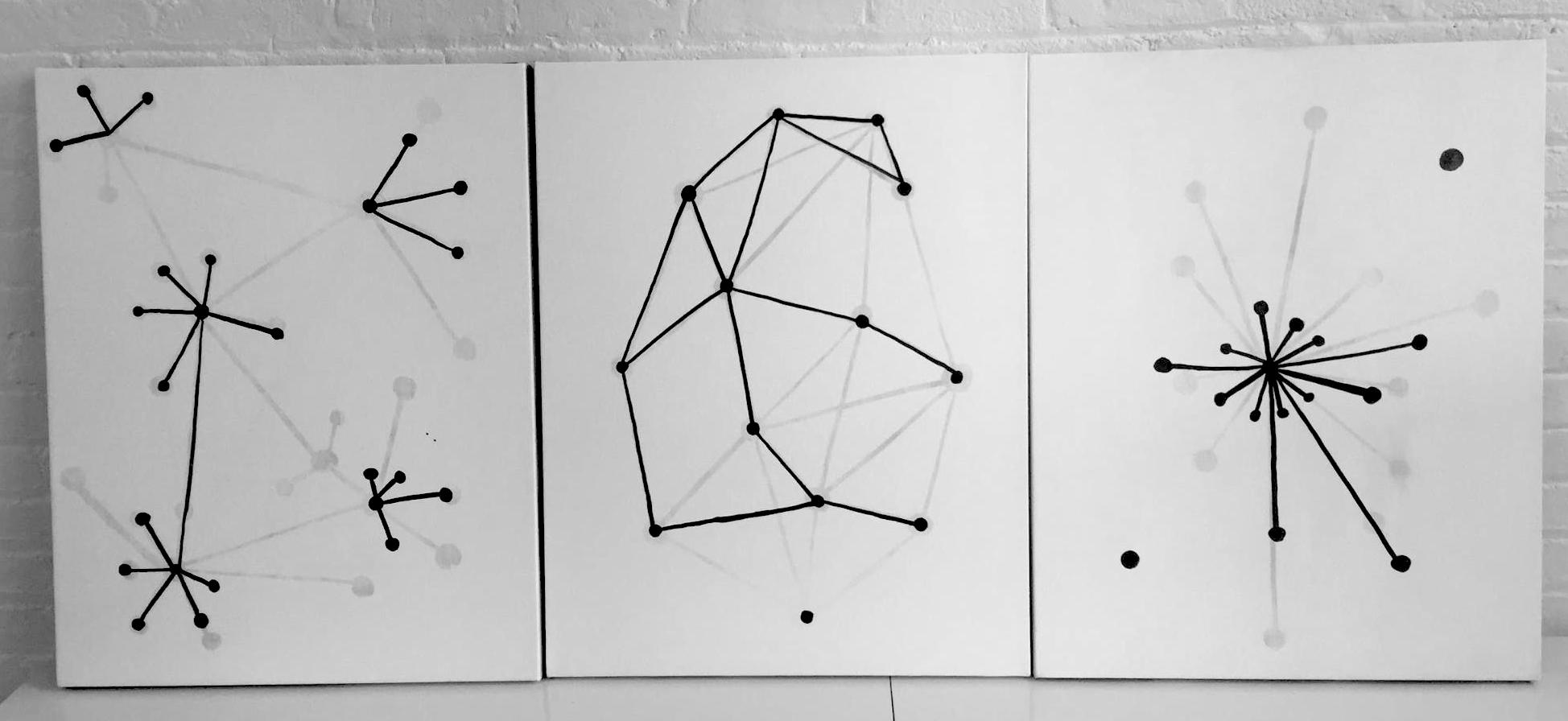
In the far right you see a centralized network, there’s a very intense connection in the middle where different nodes are connected to. On the far left there is a decentralized network where there’s a variety of centralized networks that are connected to each other. What I’m interested in is the middle one, which is the distributed network. In a distributed network, each interconnected node has agency and can enact and disconnect or engage with other networks as needed.
How is the internet built today? The internet is an accumulation of these different forms of networks. It has this appearance of decentralization but its operations are centralized. GitHub is a good example of a decentralized network. I use GitHub to collaborate with other people and also do my teaching. I create my “master branch” and then students fork their own branch. When they are done working on their branch, they create a pull request for me to merge. Although GitHub supports decentralized collaboration, at the core of it, the nature of its repositories are incredibly centralized. It’s optimized for centralized forms of control and command. These words, such as control, command, server, host, all have a relationship to military action. It’s related to how the Internet, or the network as we know, has been created and continues to be used.
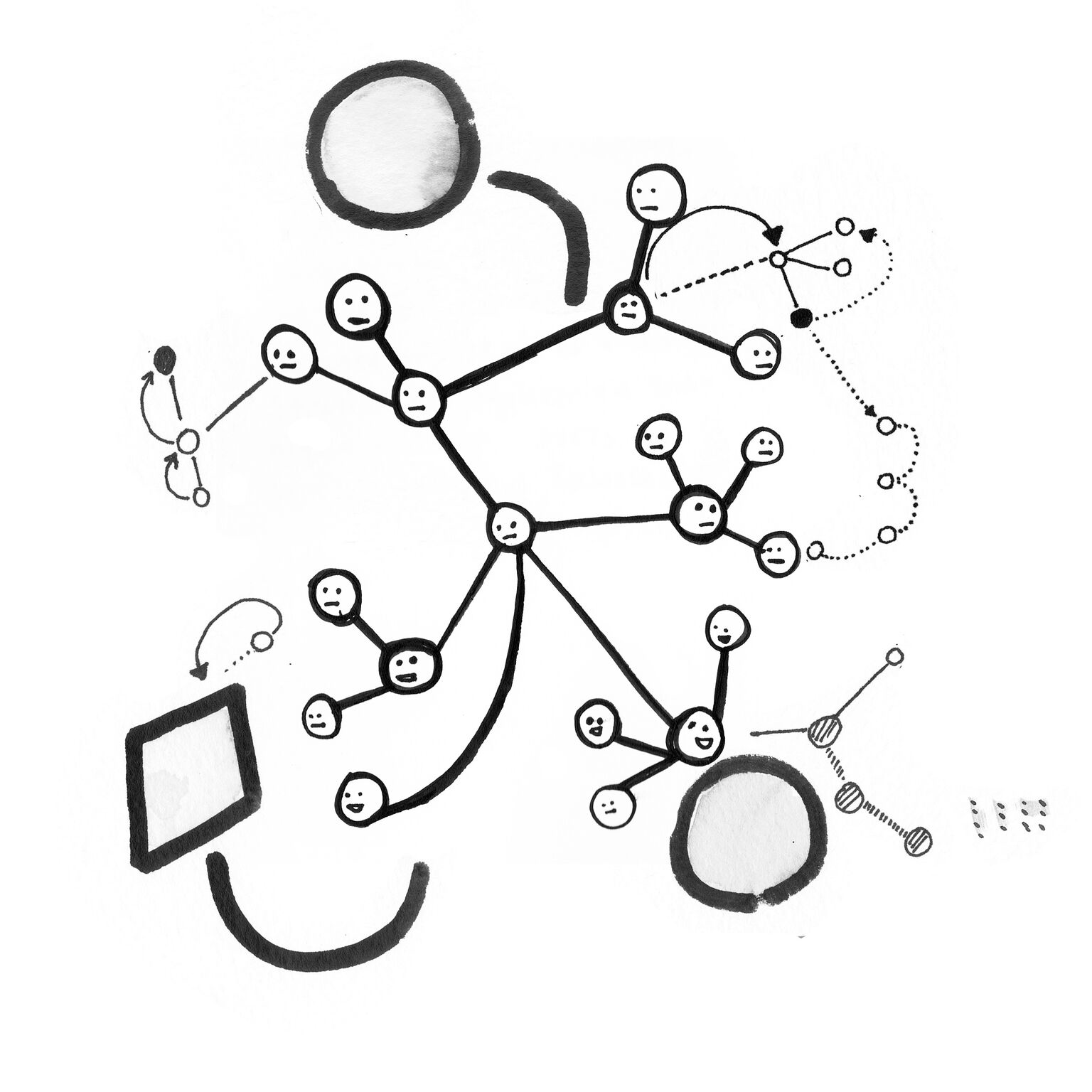
We often hear words like “cloud computing” which abstracts the computing infrastructures into beautiful and playful images. We often see images like Amazon web services logo. You can see the blobs of clouds and these boxes that could either be packages that you ordered or packets of data. There are obscure raindrops coming out of the clouds and it suggests that the computing is possible everywhere, that the cloud is like water, like humidity. However, we know the “cloud” is a massive interconnected physical infrastructure which exists across the world.

Ingrid Burrington writes in “Why Amazon’s Data Centers Are Hidden in Spy Country” for the Atlantic, “The databases alone are not archives anymore than data centers are libraries, and the rhetorical promise of The Cloud is as fragile as the strands of fiber-optic cable upon which its physical infrastructure rests. In part, the success of Amazon Web Services - arguable the success of The Cloud itself at this point - lies in its ability to abstract infrastructural problems into logistics problems.”
Burrington’s comment sheds light on the most common use of cloud computing services as machines of bureaucracy. We often use the cloud computing for office tasks, such as spreadsheets, documents, or slides. We have grown accustomed to this abstracted notion of computing to logistics. Logistics is a part of the infrastructure equation. When we become accustomed to conveniences of such services, we are also growing dependencies on the physical infrastructure.
I’ve been thinking about computing for a while, especially thinking about how to give form to it, visualize it, build it, and be a part of it with projects like the Handmade Computer.
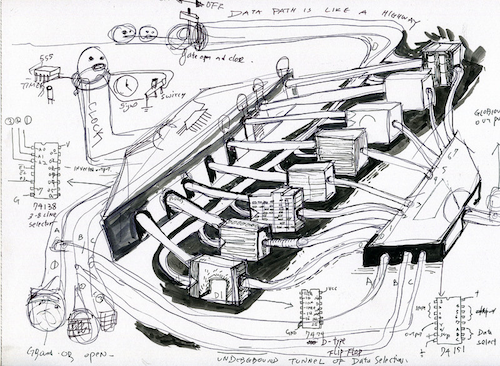
Computers are often compared to urban infrastructure. In my drawing above, there are buildings, highways, and people passing through different nodes as passengers. Sometimes there are traffic jams; sometimes there are roads that you have to pay to get to. When you’re building hardware, it really looks like urban planning. It’s tempting to think about computer architecture as cities, data path as roads, and people as data which all operates under a massive clock. However, the metaphor of city as computer is not complete.
In an article, “A City Is Not a Computer” for Places Journal, Shannon Mattern writes, “Our current paradigm, the city as computer, appeals because it frames the messiness of urban life as programmable and subject to rational order.” Mattern is criticizing this notion of cities as a computer and computers as a city. “There is more than information processing going on here. Urban information is made, commodified, accessed, secreted, politicized and operationalized. She is pointing to the fact that cities are not simply computers. The kind of activities that happen in cities and societies at large are not just information processing. Life is more complex than just data.
So this leads to some of the questions that I’ve been thinking, why we need to care about the distributed web. The first question I ask is: How can we resist the capitalist means of control and instead care for each other through the network? The word care is important here because I think about care as an alternative to control. Control is how the network operates, The Internet consists of control mechanisms from different nodes. I’m focusing on this word control because Gilles Deleuze talks about “societies of control” in contrast to “societies of discipline.” A society of discipline is like a confined space of imprisonment, while on the contrary, a society of control is more like a private highway. The free-floating traffic of information travels in what appears to be open space, but in reality it is highly regulated because of the infrastructure on which it is built.
We optimize ourselves to operate within control protocols, efficiency and compliance to terms of service. We attempt “Search Engine Optimization” of the self. Meanwhile, the society of control does not provide space for the us to take agency and take care.
With these questions, I invited a group of colleagues from Data and Society and students from the School for Poetic Computation to share their thoughts on the concept of the Distributed Web of Care.

Kelly Monson
I was thinking: if we want to keep this a public and decentralized network, how do we establish a rule set or a code of conduct that people are trusted to follow? How do you establish this without using a form of policing? That’s an important distinction. Also I think a lot about how if you have this network, how can you keep it from being exploited? If you have a tool that people use, then, depending on how big the system is, there will inevitably be bad actors. Someone will discover this platform, come in, and find it perfect ground for trolling. It’s important to attempt to poke holes in a system and to see how someone could exploit this it.
Taeyoon: That’s where this notion of trust comes in: how can one build a system in a way that is structured to support care, but also is structured to build and support trust within the network?
Kelly: And how do you trust people to have empathy? Because there are varying degrees of concern for others - some people don’t have an understanding of other people’s experiences and others simply don’t want to understand. I think it’s really important to cultivate a culture of empathy and bring people to an understanding without policing. And that’s a very interesting subject because how do you force people to - well you don’t force - how do you suggest and encourage empathy?
Taeyoon: I think that’s where stewardship comes in. It’s a form of leadership that’s bottom-up and supports mutual responsibilities. Stewardship is not a question of enforcement, but how to cultivate a culture where asking for accountability is a norm. It starts with good social practices, not rules.
Kelly: Many communities tend to start small. Best practices begin to form, and eventually the community may grow bigger. How do you maintain those practices as the community grows? And then what do you do with people who are making it difficult for other people in that space? Or making it feel unsafe? Or making people feel like they’re being exploited?

Taeyoon: I think of information as continuous streams of thoughts that affect our existence together, and of data as discrete points of differences. There’s surfing going on in the sine wave of information, and the discrete components of digital data are these blocks - we have to climb up these stairs. It really comes down to what is computable and what is not. What are the discrete points of the worldview that are compartmentalized into zeroes and ones, and what are the spaces between?

We are focusing on distribution instead of decentralization. Decentralization is essential for distribution, however, they are not the same thing.
We are also focusing on care instead of control. Care is this very soft sense of responsibility and accountability. Without care, everything becomes code. We can try and write codes of conduct and codes of expectation, but until it’s executed and implemented into use, it’s just code. It’s just abstract symbols.
The big question I have is: can we code to care, and can we code carefully? Let’s think about care instead of control. Let’s think about person instead of user. Let’s try and unlearn instead of machine learn.

Question number two: how is the distributed web different from the decentralized web? To answer that we need to figure out how the web actually works today. I’ve invited Hans to give us a brief summary of how the architecture of the web is built today.

Hans Steinbrecher
We have 3.2 billion people on the internet right now, and we have more devices on the internet than actual people - roughly 23 billion devices. And when I say devices, it’s not the computer with a keyboard necessarily, it can have a monitor or not, it can be a phone, a Chromecast, a thing in the industrial sense, it’s a connected CPU. Right now we have 23 billion devices and out of those we have clients and hosts.
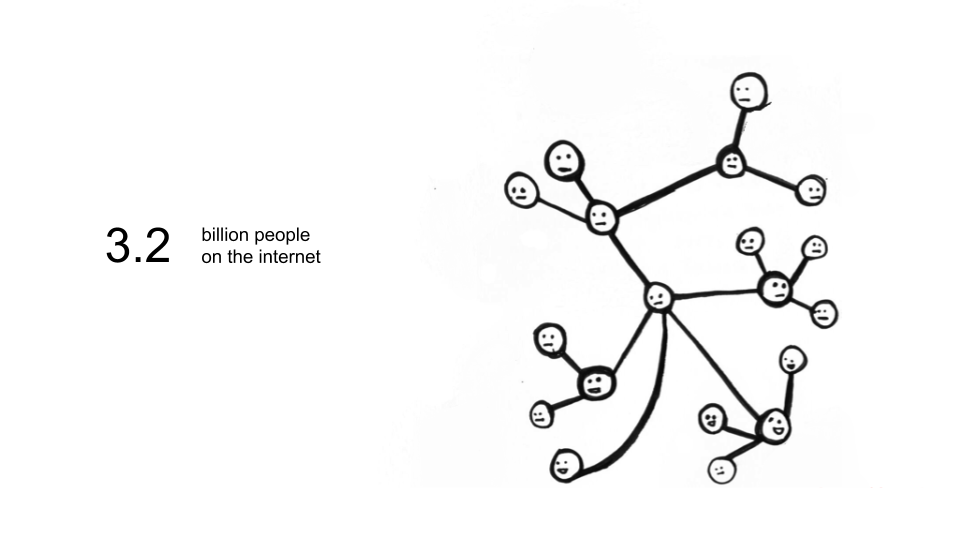
The hosts essentially serve content, they are servers and there are about 75 million of them. All of those servers have addresses, and we call those addresses domains. We have around 200 million active domains right now, and the domains are the applications, the companies, the dot com, and each of those servers essentially has a lot of data in them and databases and data centers.
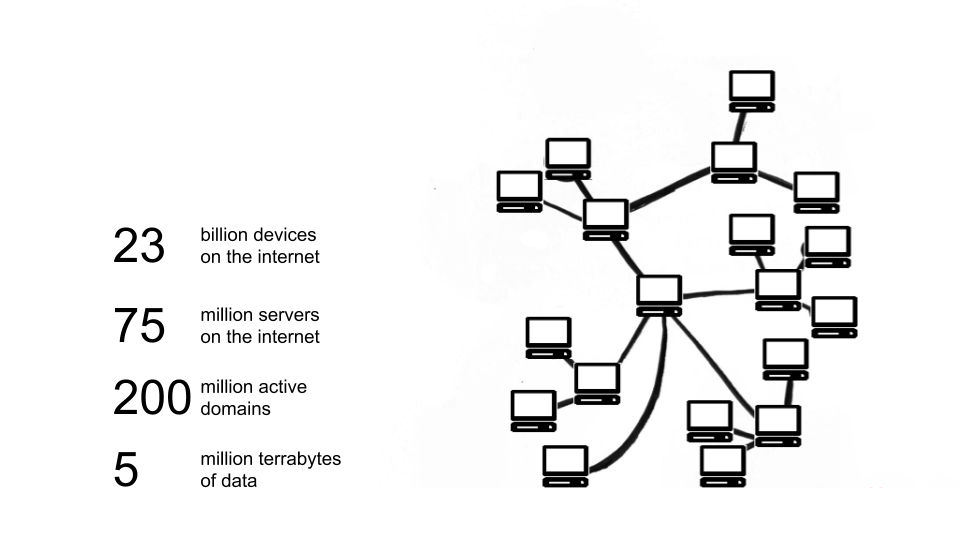
These servers in the old school sense would be like me sitting at home having a server and jamming on it, but in the modern sense, just as we saw, we have Amazon Web Services (AWS), we have Google Cloud, we have Microsoft. We have these big cloud providers and they have essentially split into clouds. It’s always debatable how much is actually in the cloud but probably around 90% of computation is happening in the cloud. And it’s very, very centralized. That’s the point here.
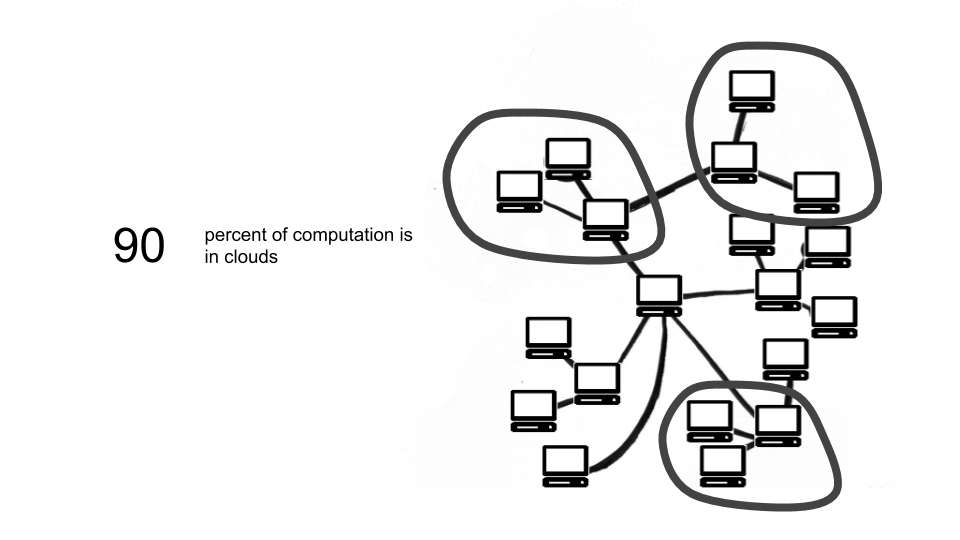
Taeyoon: So it’s physically centralized in a couple nodes, and corporations own access as gatekeepers to these clouds as well. So it’s doubly centralized.
Hans: The cloud providers offer you so many services and cool new techniques: machine learning and fancy databases, a lot of cool features that make building computer architecture today quite fun and accessible. If I work on Snapchat and want to focus on a cool experience for you, I’m probably not going to build an old infrastructure but rather I’m going to go to Google Cloud and say, “Hey I built my infrastructure on top of you because you have all these cool queues and cool distributed memory storage and stuff like that.”
Taeyoon: But it also means that they can take it away from you at any time. So it’s pricey and also you don’t really own it.
Hans: Yeah, that’s the point here, it’s really like private property. The companies think, “What’s going on in my cloud is my business. I’m the boss, I’m host, and I decide how transparent I am. You won’t know what’s going on in my cloud, in my back-end.”
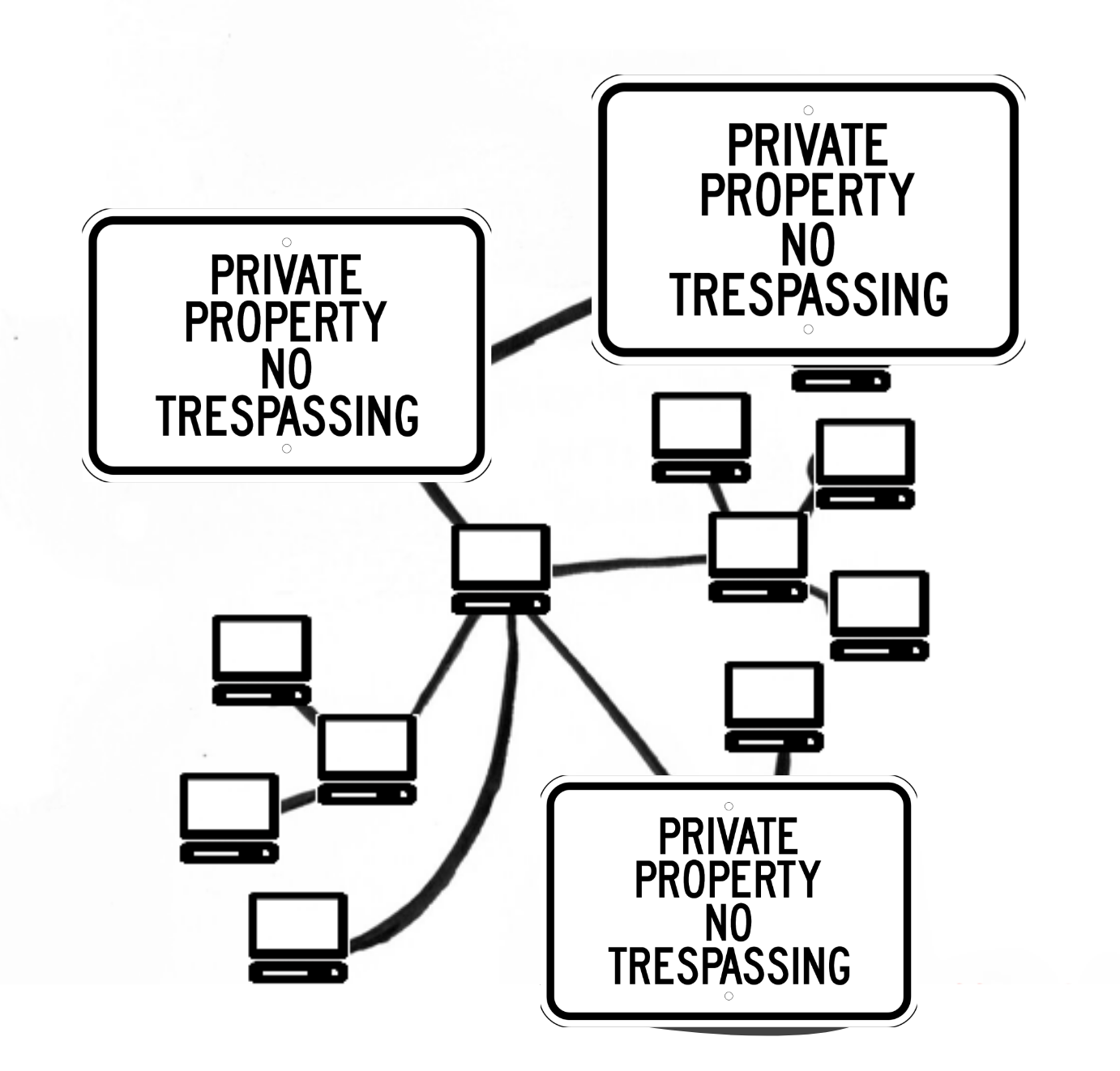
Taeyoon: The key concern here is privacy. Because it’s “private property” but we don’t really retain ownership of this data, the company can do whatever it wants to do. We’ve seen many historic and recent examples of abuse.
Hans: Intentional and unintentional abuse, probably. If I, the company, own all of this data and it’s my responsibility to take care of it–care in the sense of really fixing all loopholes where people can access it–it’s very vulnerable.
In the cloud, there’s a lot of effort going on to provide their services–there’s a technical effort just to keep the service up. If I’m a high-scaling business, I want to make sure all of this is available to you, I want to never be offline. I have people paying for this. The natural involvement of the engineers in the backend is this famous thing, the “CPA theorem”: you cannot be consistent, partition-tolerant, and available at the same time. You always have to deal with trade-offs and mitigate a bit. So, you distribute and you network over regions, and across the regions you have multiple duplicates of your service, making sure that there will be backups wherever there’s a failure. For example, you might send a snapchat that uses the Google Cloud regions across the world.
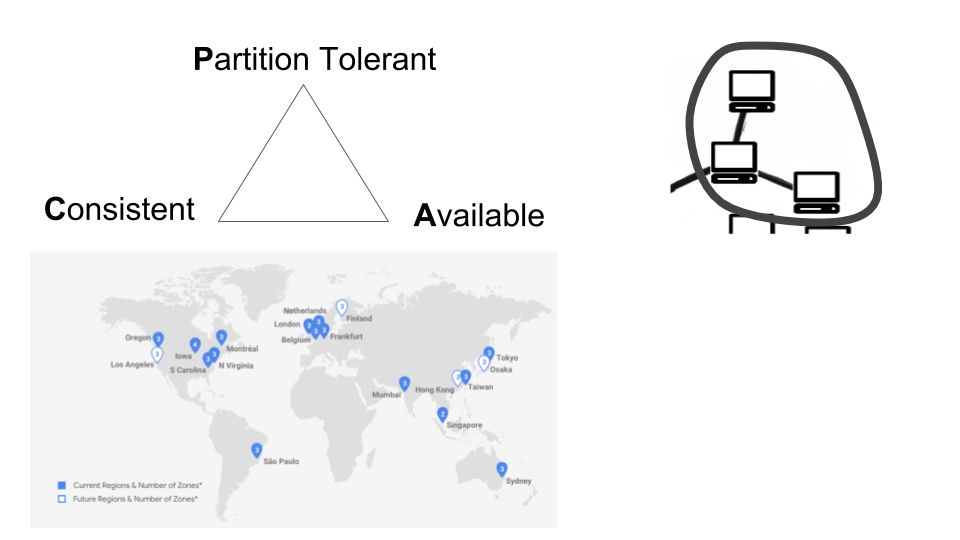
One problem essentially is that we don’t know exactly what happens with our data even though a lot of effort goes into keeping the service up so that in one form or another, you always access your data from a centralized point of view. Let me show you a concrete example through video-conferencing:
Let’s say Taeyoon and I are about to do a Google Hangout. We open the browser on our device and punch in the domain, then we go to a name server which resolves this domain to an IP address. This IP address is the address that Google associated with it when they bought the domain. Before we actually go to the server itself, we load the certificate which is associated with this domain to make the connection encrypted, so that no one can access it just by spoofing on the wire, which anyone could do. So, now that I have the certificate I can actually access the data.
The first thing that happens is loading the static assets. The static assets are what your application contains: your html, your JavaScript, your styles. And those static assets are hosted initially from the cloud provider–in this case, Google cloud–but they are distributed outside of this network in the form of CDN (Content Delivery Network). We connect to the closest node, and now that we have the application running, I want to have a video stream with Taeyoon. In order to do so, we will exchange session descriptors which will go through the Google Cloud servers and say, “Hey, I have a video cam and a microphone, and this kind of codex, framerate, and resolutions,” and I will send this to Taeyoon through centralized servers over TCP protocol, websockets, standard techniques, etc. We exchange session descriptors, and part of that is where the stream will be coming from, which is the IP address. In this case, Google Cloud is a centralized video or media bridge, so this IP indicates to Google hangouts one of their centralized media bridges. We will open a peer connection to this media bridge and establish a stream. A peer connection has multiple media streams and now we get going. The media streams are also encrypted, so the protocol is called RTPS. Google also has keys, so the stream itself is encrypted over the wire, but the media bridge is accessible and decrypted. Content can be indexed and accessed in one way or another, allowing features like muting, mixing, but also monitoring.
Taeyoon: The question really is: when this data is indexed on the cloud, do they retain some parts of it, or most of it?
Hans: What’s the question? (laughs)
Taeyoon: Well, I guess that’s a question that they can’t really answer because it’s private property.
Hans: Yeah, it’s essentially this lack of transparency. Well I don’t know if it is. But it could be.
Taeyoon Choi
So, that’s how the internet today works. Next, I’ll do a brief introduction to Distributed Data and Network to give you an overview of what we’re thinking about. I’m very new to this topic, and what I’m going to be covering is a very small fragment of a larger initiative. Some of these projects might be works in progress. What I’m attempting to do, along with my collaborators who share different ideas and facets of technical development, is to begin to think about the kind of network that we want.
One project that I’ve been following is IPFS, which stands for Inter Planetary File System. It’s a p2p, peer-to-peer, file sharing system that allows you to be a node, where you can share your data. One of it’s missions is bringing permanence in the web, as an alternative to how the HTML links usually rot over time, and we end up with this very impermanent web where we cannot keep track of all this data that we are building. There are more interesting technical details to IPFS, which I won’t get into.
The project that I’ve been following more closely is the Dat Project, a distributed data community, or DAT. It’s filling in some of shortcomings of traditional p2p. For example, with Napster or BitTorrent, it’s pretty convenient to share an mp3 file, like a Britney Spears song. Britney’s song is really easy to share because it’s a piece of static content that is shared from multiple nodes. However, what traditional p2p is not very good at is updating content over time. If the song changes, how do we know which is the right song and which version should be kept track of? The Dat project is addressing those issues by making it easy to have a version controlled history of this file. Another shortcoming of p2p is that it’s difficult for large dataset such as a few terabytes of data. Technically BitTorrent breaks things apart and then puts them back together and with large datasets, the integrity of the data could be compromised in doing this.
These two projects, (Dat and IPFS), are closely related. Dat actually uses IPFS among other things to have this decentralized modes of sharing data. However, there are very important differences between them. Dat is developed by teams in Portland, Denmark, Taipei, Berlin. IPFS is concentrated in Palo Alto and has some venture capital funding behind it. They’re both open-sourced, but Dat is based on foundational support by a nonprofit. Their visions are slightly different. Where IPFS wants to be a permanent distributed web, Dat focuses on sharing data over large networks. The business model is very different as well. I believe that IPFS is related to FileCoin which is a a blockchain-based storage network and cryptocurrency, and they had an initial coin offering as fundraising for their revenue. Dat encourages users to host their own data or use subscription based services like Hashbase.
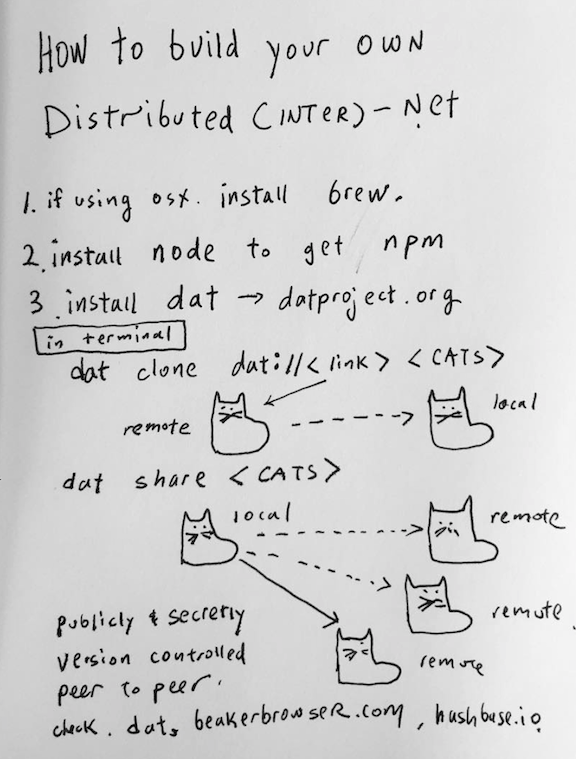
I’m going to walk you through the basic steps. There are a couple ways of accessing it. After you install Dat, You can use the Terminal to access Dat, type “dat clone” and a long address (hash), and you’re going to clone this address into your folder called “Demo.”

And then it’s cloning 25 files. There are 3 connections right now so that means that there might be three other people sharing or cloning this data right now. Dat syncs quickly, and just like that we have cat pictures, somebody’s cat pictures that they felt like sharing on the Dat network. That person has the private key, which means they can update or take down their cat pictures at any point that they want. But the other nodes that are sharing the cat pictures do not have that private key: they have a public key and can access them, clone and mirror them, and distribute them, but they don’t have ownership of that data. By sharing a public key, you’re giving permission for others to re-host your data. These added or shared hosts can’t change or write new content, since you are the owner of your data, but they can host whatever data they have accessed from your Dat.
Now, I want to talk about how to get started with dat from a less technical standpoint. There are many ways to clone someone else’s file on the distributed web. A good place to start from is the Beaker browser. You can download Beaker in your operating systems and you can start to share data with other folks through it.
I’m greatful to Tara Vancil and Joe Hand who gave detailed editorial feedback for the next part.
When you want to share your cat, you can share it by publishing your local copies. I don’t have a cat, so I made a cat drawing
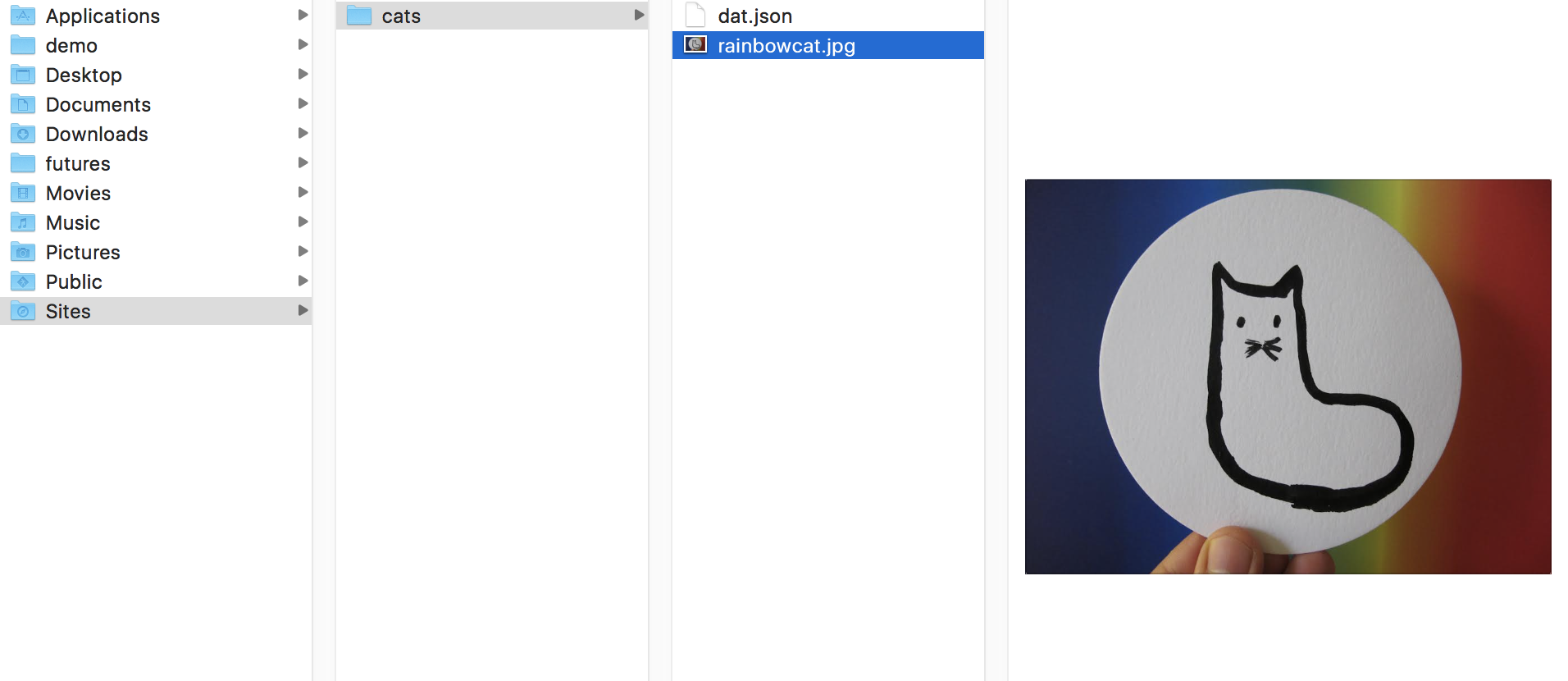
If I feel inspired to share my cats, I can use the Beaker browser to add my folder called “cats” and then change thefile name to “rainbow cat.” I have reviewed the changes, as Beaker keeps track of different versions, and when I’m happy with the files, I publish the folder. The cat that I drew is sitting in the hard drive of my computer. But I have shared it over the Distributed Network. And I used Beaker to host and share the cat drawing.
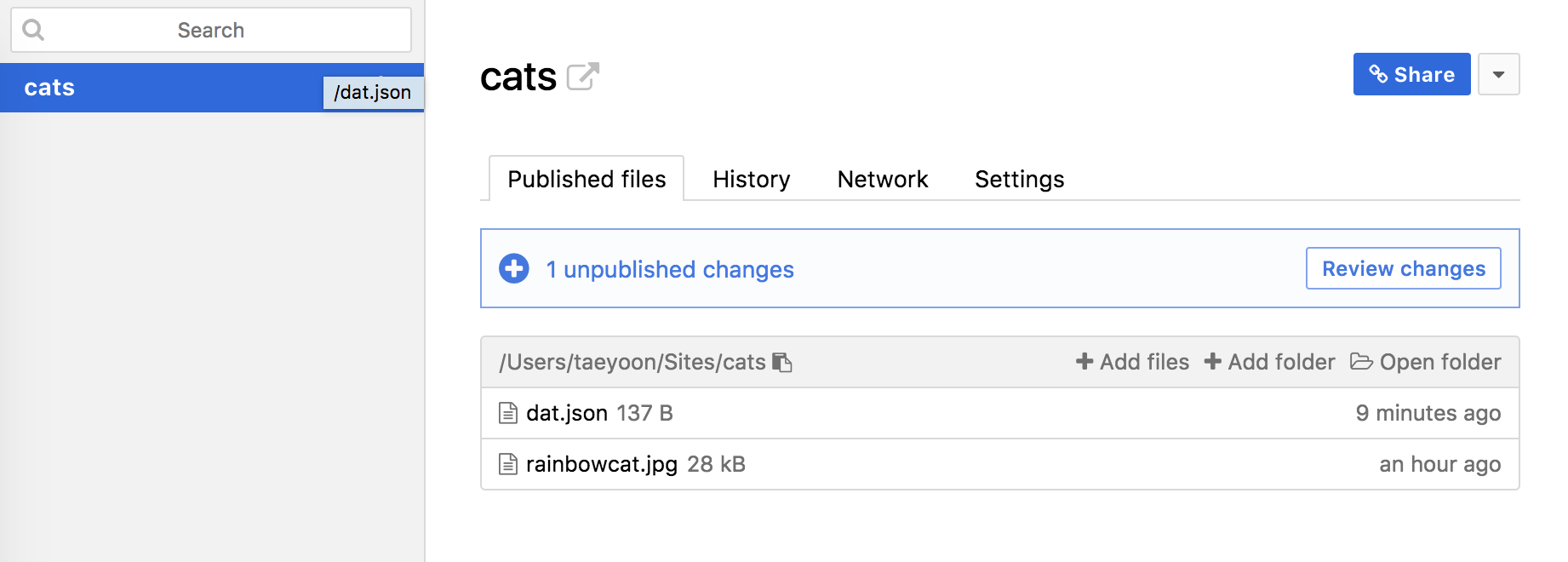
And my cat drawing just got a unique dat key – dat://f7015de28d02cfb99debc6545aead91418b61c4ca74b905837be2608ed13f21a If I share this key with you, you can clone the cat drawing. However, if I don’t share it with you, you can’t access the file. In order to access the file of my cat drawing, you would need to know the actual address.

The great part about this way of sharing is that whenever I change the cat, it keeps track of the history and you can address those particular moments in time.
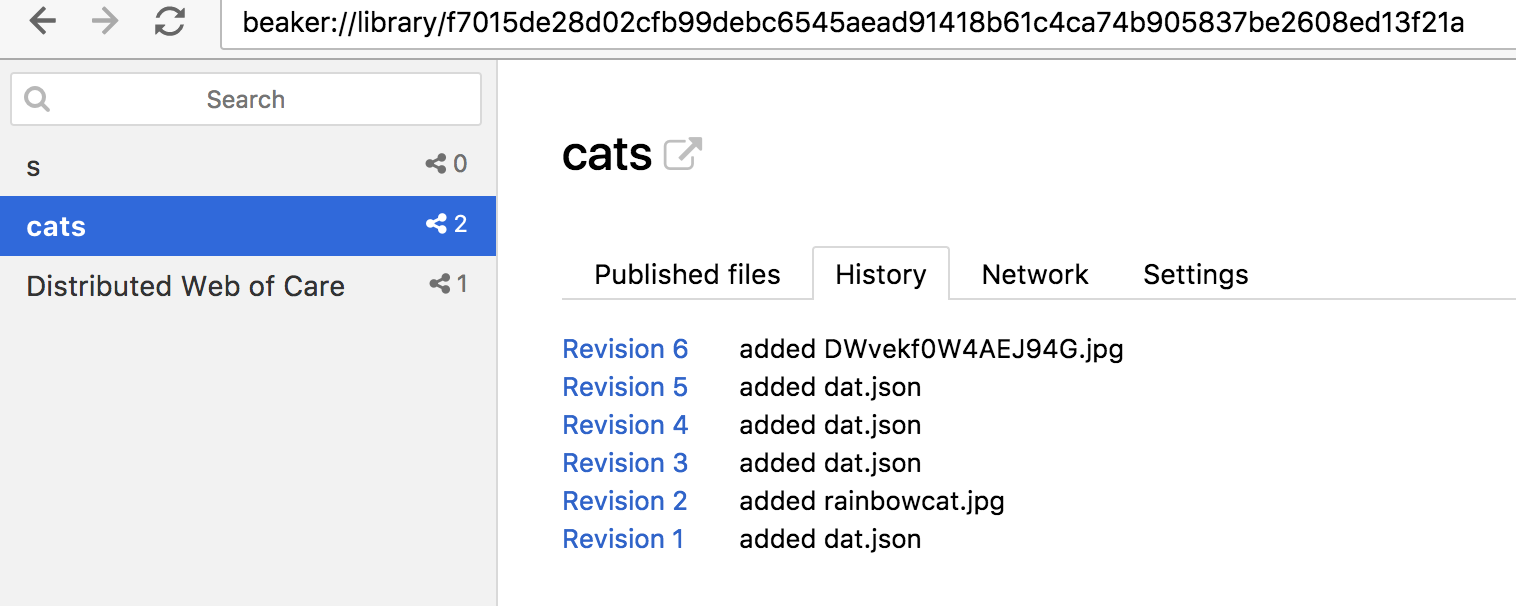
Dat URLs are cryptographically unguessable, meaning you can only discover and decrypt the files for a dat if you know its URL. Nobody else can access it unless they know the specific address. By publishing the file and sending you the key, I’m inviting you to access the cat drawing on the computer that I’m using.
On a related note, in a little bit, I’m going to ask Sara to help us understand the concept of hash from a technical perspective and use-case scenario. Basically, hashes change over time depending on the versions. So as you can see at the very end there’s a plus six, so I’ve made six changes and it keeps track of that.
There are many ways to get your own copy of someone else’s data and host or share it yourself. One way is by cloning data from remote into local. I’m going to clone pictures of Tara’s(who is one of the people behind Beaker) cat Sasha into my computer by using Beaker and now I have Sasha’s photos!
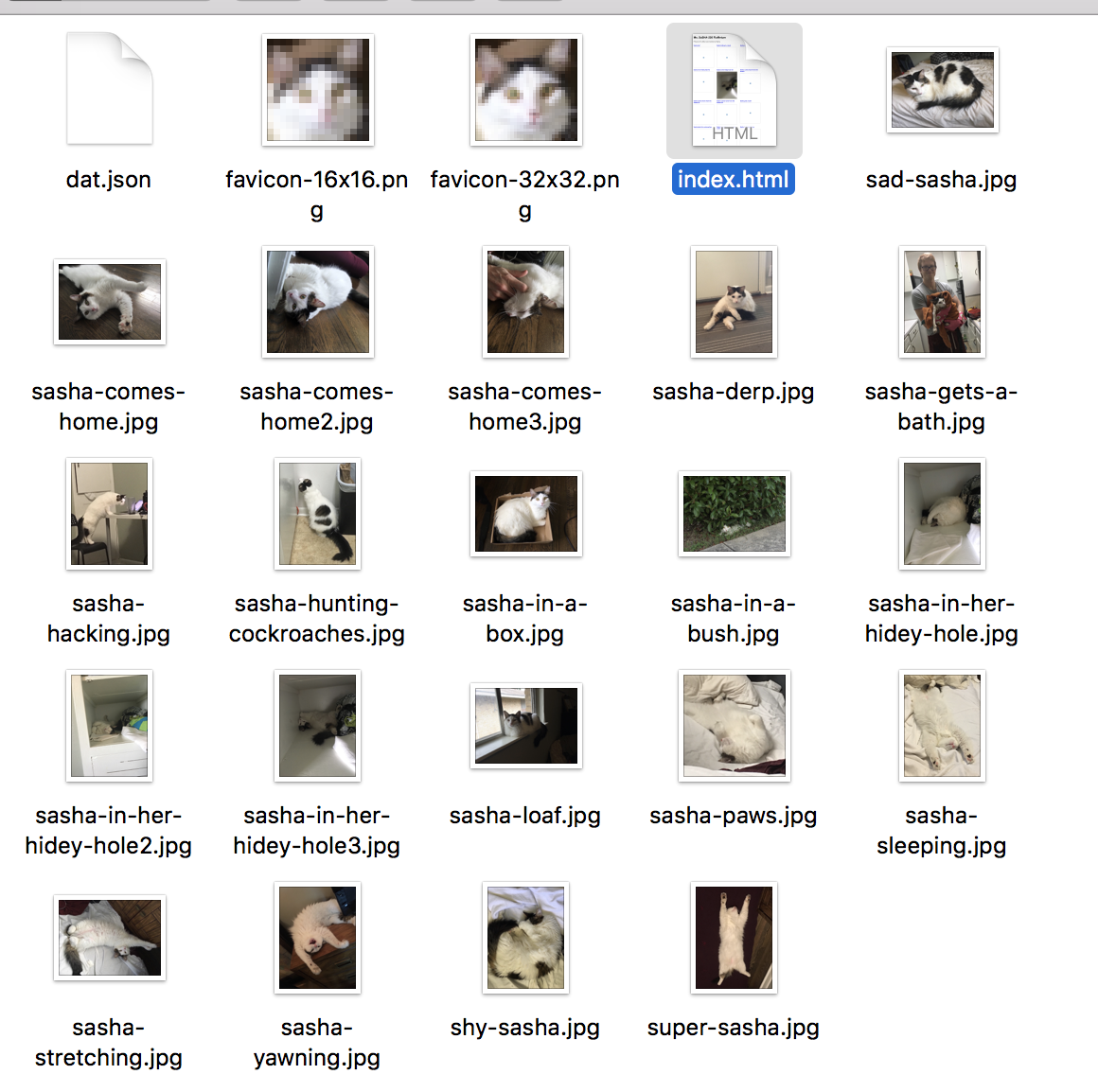
Beaker browser also has a built in tool for making editable copies of any Dat website by clicking “make an editable copy.”
The interesting about peer to peer sharing is the full control over distribution of data. When I stop the Beaker browser, the cat drawing is no longer accessible to you, unless you’ve already cloned it. Once I’ve shared the URL with friends however, they can rebroadcast the files, allowing other people to seed them and them make accesible once I’ve stopped using the Beaker Browser. This allows for ways of getting around having to host the file on your browser or your computer, you can let other people host the file on their node as well or use hosting services like Hashbase which I mentioned earlier. This means that you can either make your cat available for other people and hold them responsible for it when you don’t want to be, like cat sitting. You can also use DAT desktop app to clone remotes.
Right now, I have a lot of questions: how does this actually work? How we can specify different use-cases, like when we want to make our data available for certain people but not all people? How does the encryption work and how can we make the data perish if we don’t want to make it available? These are technical and philosophical questions that Sean Dockray, an artist and a friend who inspired me to look at this, has been helping me understand. We are planning to share some of these resources soon.
The really important part is asking what can we do with the distributed web. I’m asking Callil, an artist, designer, and developer to talk about some different implementations of these ideas.

Callil Capuozzo
I organize New Computer Working Group where we collectively research new, more fluid forms of computing and actively participate in the p2p web. I wanted to share some of the networks that I’m part of and some other examples of what the p2p web can look like.
First, I want to mention that there are a lot of different things that make up the p2p web, such as social networks, file sharing, scientific data, web tools, art and blockchains. Torrents are still a very big part of it. But these days with the emergence of some new technologies, a lot of stuff is beginning to be centered around what it means to have social networks that are p2p or distributed.
The first example is called Scuttlebutt, which is an open platform or an open protocol for social networks that are fully distributed. It’s a different implementation than Dat or IPFS but very similar. As a user on the Scuttlebutt network, when you make a profile you get a hash that is your user profile. At first you don’t have any connections until you make a friend or you add somebody else’s hash to your network. So, if I add Taeyoon’s address to my network, not only do I get his messages that he has posted over time, but I also get access to his portion of the network, his friend list essentially. If I then follow another person in Taeyoon’s network, the area of the social network that I can access grows a bit more. In this model, you can see how these nodes begin to build up a representation of your local network that you’re participating in. What’s really interesting about this is that unlike Facebook or Twitter, there’s no central server that defines what that network is. This means you can have these small local spaces without connecting to a larger network. Or, you can go and connect to as many peers as you want. Scuttlebutt has also implemented interesting things like channels, which define how you hashtag a post. These channels can be empty if you don’t have a peer that has participated in it, meaning there’s no way to participate across networks unless you build bots, which are called “pubs” in the Scuttlebutt world.
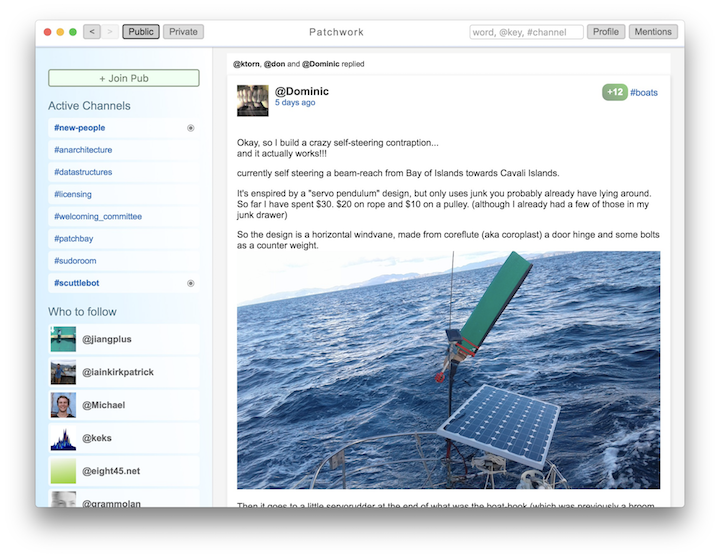
The next example I want to talk about is a social network called Rotonde, which is built on Dat. I want to use this example in comparison to Scuttlebutt to show the divergent and different ways of building p2p social networks. Rotonde is similar in the sense that you really only get access to content when you follow people through your peers. One of the major differences between the two networks is the way they store your files on your computer. Scuttlebutt stores files in a non human readable hashed table, a hidden .sbb file that is essentially gibberish inside. With Rotonde, similar to how Taeyoon was showing you could upload or download your cat file, your profile contains an image, a JSON file of all your posts, and a web app– an index.html that renders the view. Your JSON file also includes your following list, so when loaded all the posts from those peers’ JSON files are also loaded into your feed. Because it’s a human readable front end, I can go in as a user and edit the page to look however I want. As a user of Rotonde, I don’t have a centrally defined look, feel or behavior of the social network. I can make the background blue. I can make all the posts into expandable pop-ups. I can do whatever I want because I own the front end and I own the definition of how this social network is expressed to me. As a web page, this is in contrast to Scuttlebutt, where there is more centralization right now.
We’ve looked at social networks as one way the p2p web is being built. Another interesting part of the p2p web is publishing. Having access to publishing is an important part of what it means to own your data and define how your words are represented online.
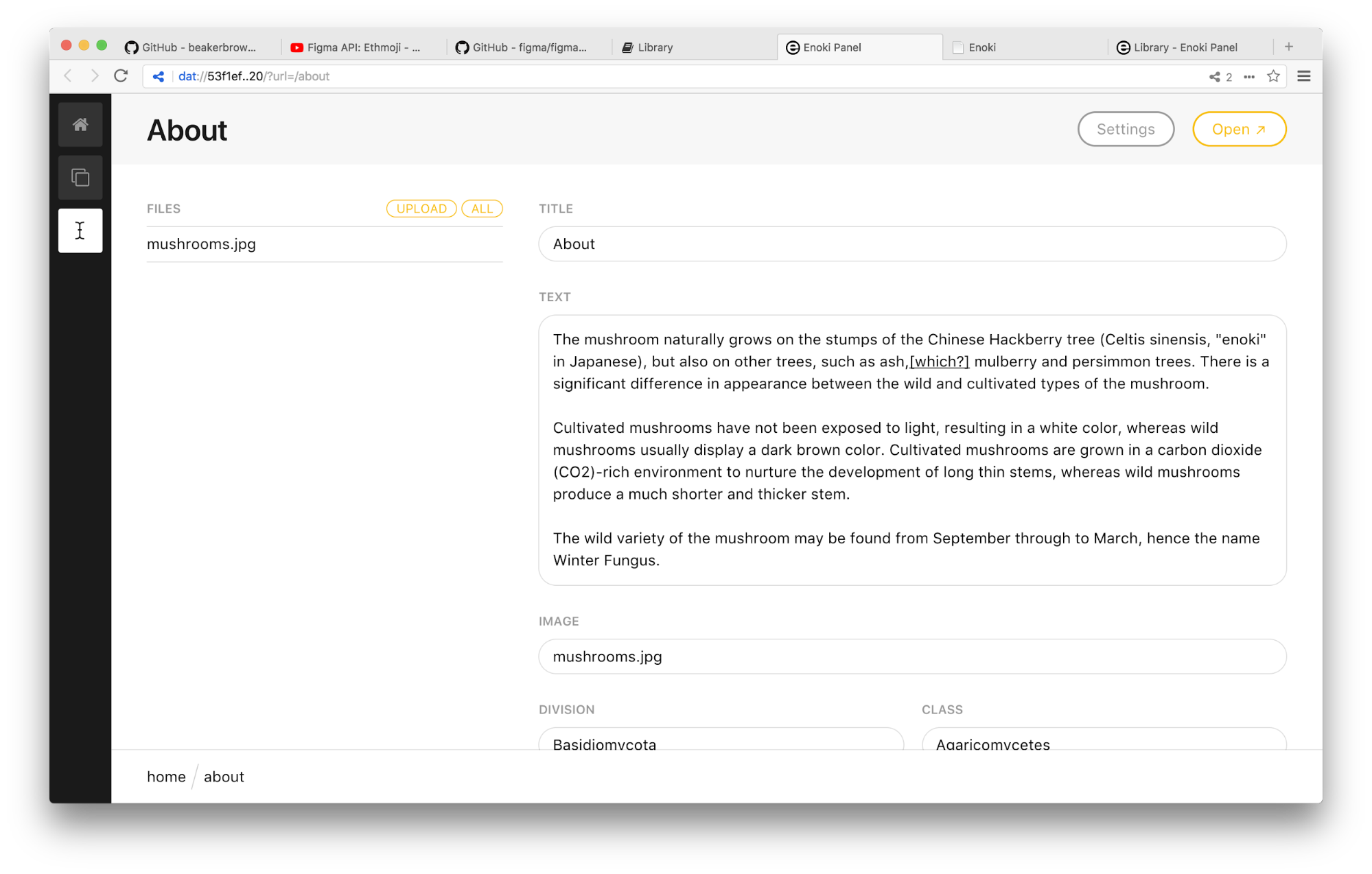
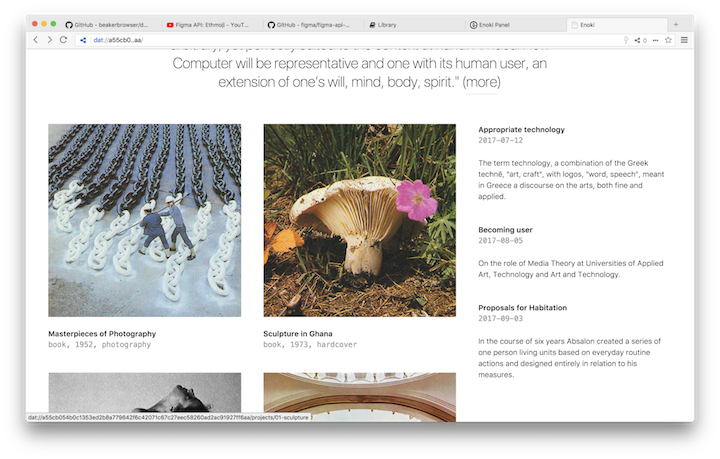
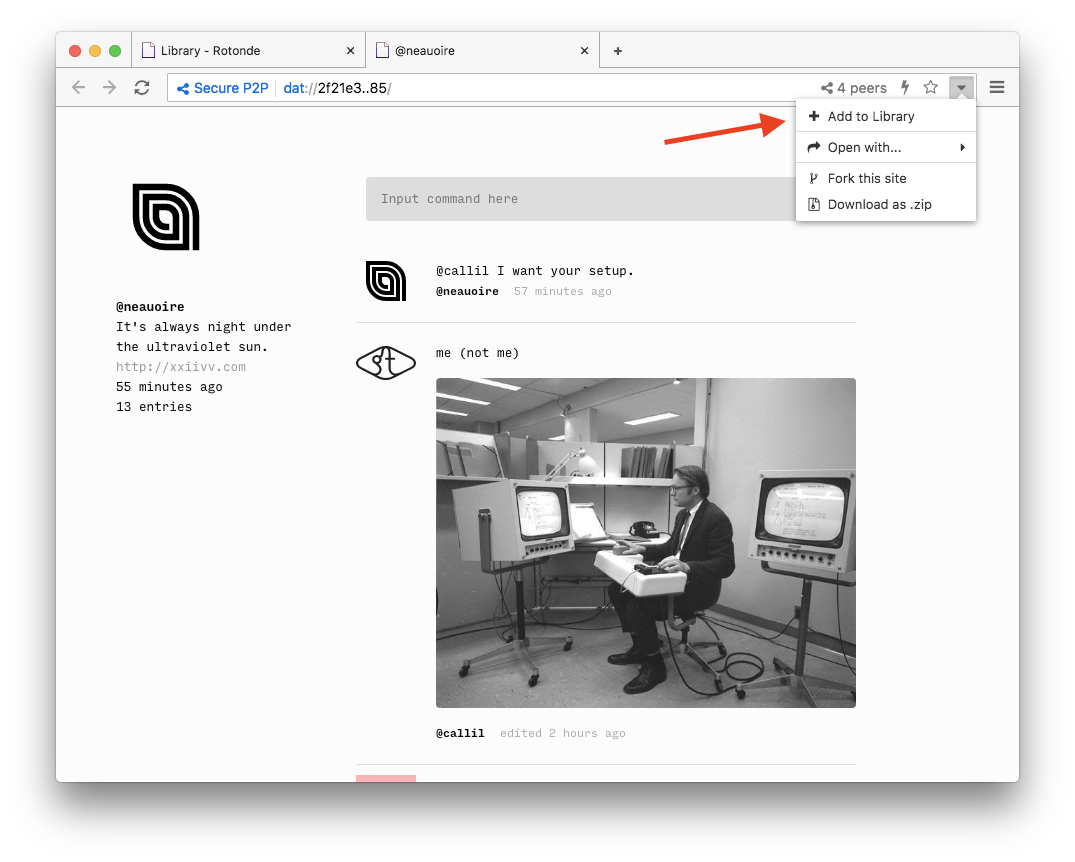
Enoki is a project which gives you the ability to build websites right within Beaker Browser. Similar to the cat example, you go to panel.enoki.site and you basically fork or duplicate an Enoki project. This will download the whole entire project onto your computer and then give you access to an editor and a front end which you can instantly start to publish from. Once you’ve downloaded that, you receive the Dat url to share into the network which becomes accessible as soon as you hit publish. This platform is a really easy way for getting your stuff out there and then retaining ownership over it.
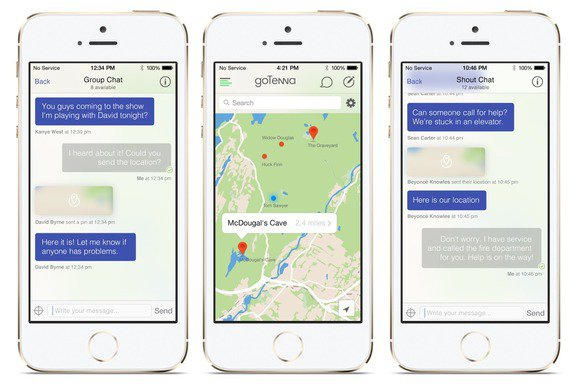
Some of you may have heard of Brooklyn-based Gotenna. We’ve been talking about what it means to have a p2p web which is accessible through a browser in the same way we already access web content. Gotenna is building something with similar ideals to this but by using physical devices. They provide a low power radio that can be used to make a mesh network between any other Gotenna user in the world. When you turn the device on it becomes a discoverable peer that any other Gotenna user can search for. So it starts to make a mini internet for you, a small community. It’s really good for places that are out in the wild which don’t have internet access. It also suggests the idea that you can build smaller networks that don’t necessarily have to be connected to the internet at large. With Gotenna, you don’t have to be connected all the time. You can go offline and make a smaller, more protected internet.
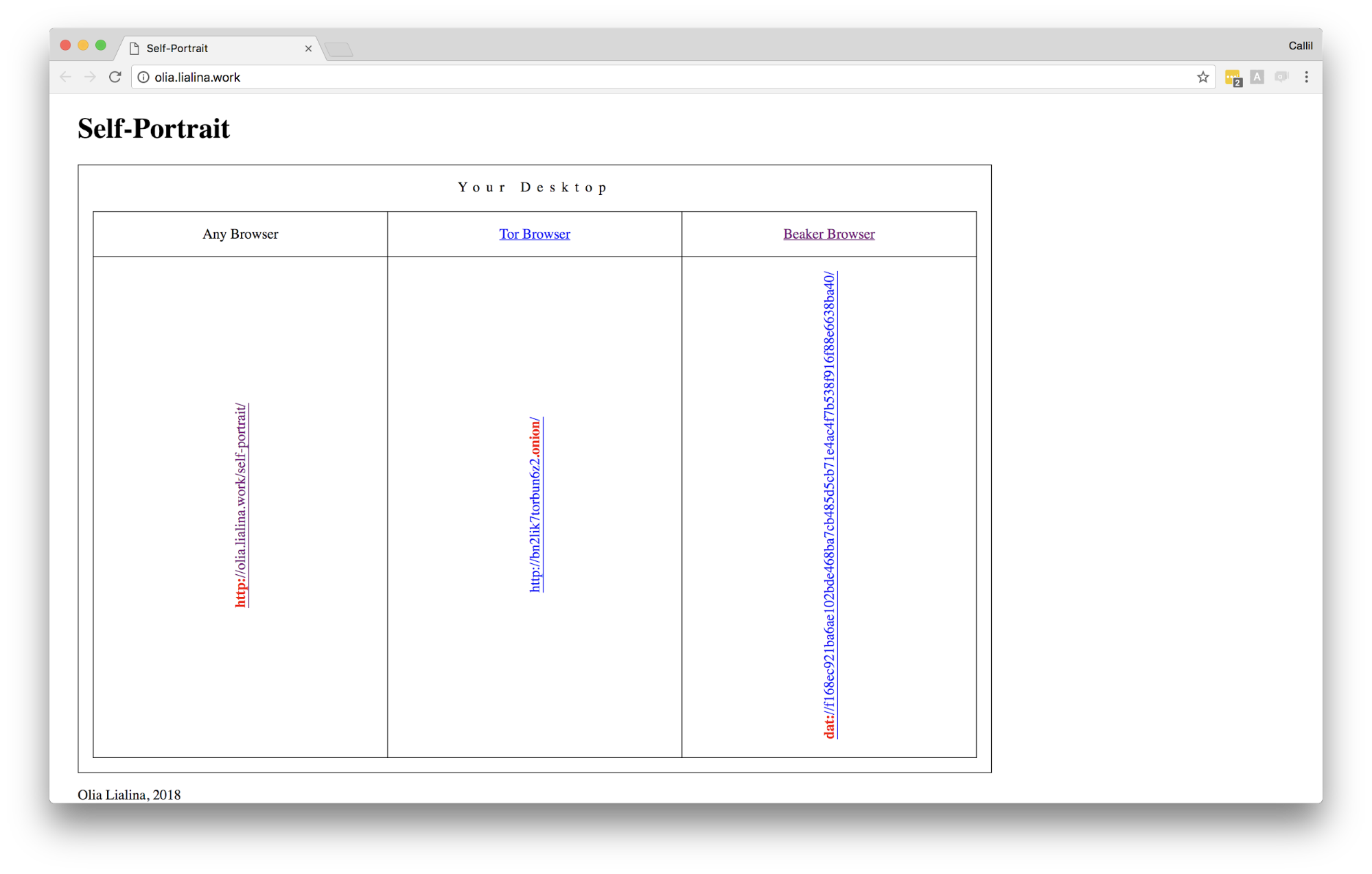
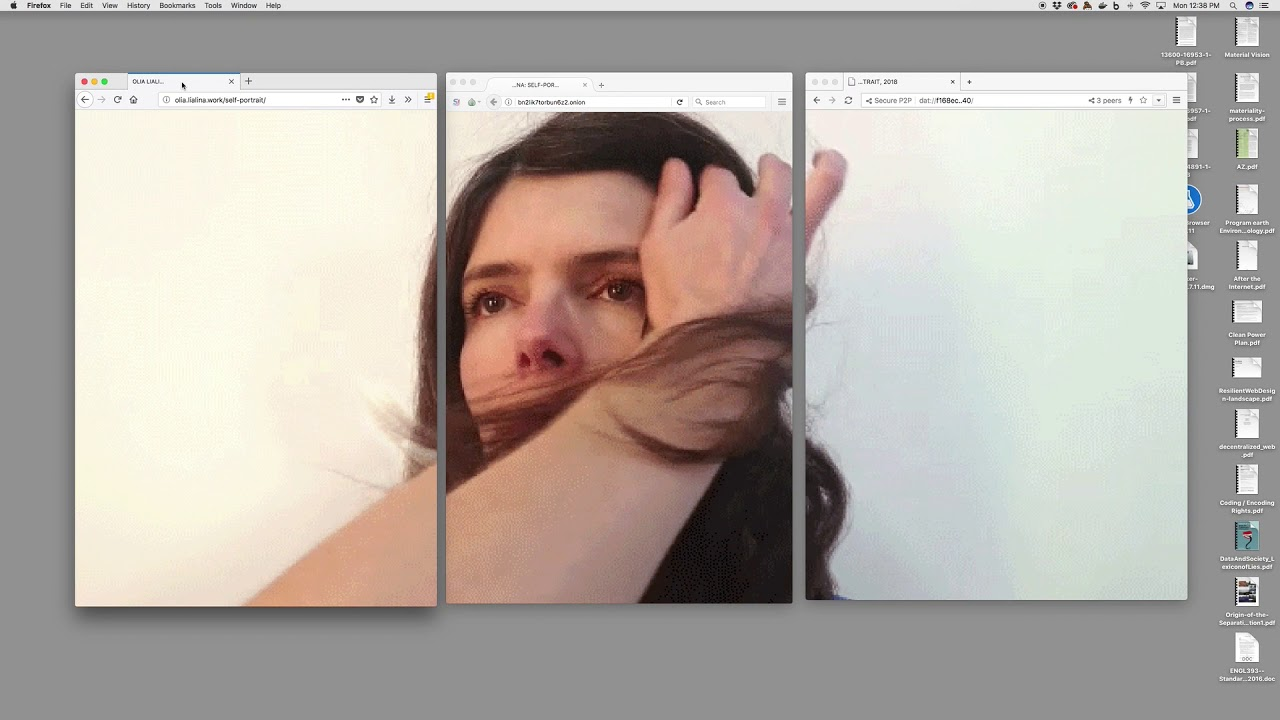
I also want to mention that p2p spaces are perfect for art and for different forms of expression because of the ideals they capture. Some of you may know Olia Lialina, she’s an amazing artist that has done tons of work over time. Recently she put out a project called Self Portrait, which is an expression of what it means to be distributed. When you visit the website, you get a diagram guide of how you should view this site. One part of the site loads a Dat URL, another part a Tor browser URL, and then finally, a regular HTTP URL. When you load them all up you get a beautiful gif that’s in sync. This work is a really interesting representation and expression of what it means as an individual to participate in the internet at large in all these different ways. There are a lot of ways artists can use these ideas and platforms in their work to express themselves.
Finally I want to touch on blockchains because they are an important thing to mention. A lot of the ideals in these new technologies are similar, but blockchain, as opposed to social networks like Scuttlebutt or Rotonde, is built to be a network where there is trustless relationships with peers. With blockchain, you can have consensus even if you don’t have a relationship with the person you’re communicating with. This is in contrast to networks like Scuttlebutt, where you need to have explicit trust from the other person by means of following or agreeing to be a friend. This kind of social action is at odds with the blockchain model of a financial system. I think these two opposing forces is an interesting thing to think about in considering what the world of what p2p web is.

Sarah Gray
Hi, my name is Sarah. I’m a software engineer and currently a student at SFPC. I want to talk about the data structure called the Merkle tree, which is a very important piece of the distributed web in regards to IPFS and the blockchain. The Merkle tree is what gives you all of the complex-seeming addresses that we’ve seen in this presentation: strings of random, undecipherable numbers and letters.
When I approach a new data structure or a complex topic I like to break it down for myself and put it on ground that I’m familiar with so I can understand how it exists in the “real” world. If there are any human-scale analogs that can help build a bridge of understanding for myself and others, I will use them.
The Merkle tree is a way of organizing data. It’s called Merkle because the person who invented it was named Robert Merkle. I like to think of it as the data structure that lets you encode history such that you can’t go back and change it. It’s sort of like the “No Fake News” data structure.
I’m going to explain Merkle through Pig Latin. Merkle uses a cryptographic signature, but because cryptographic signatures are hard for humans to look at and understand, I want to talk about Merkle through the lens of Pig Latin so we can follow what’s happening. We’ll then go back at the end and talk about why the internet isn’t using Pig Latin and why cryptography itself is very important.
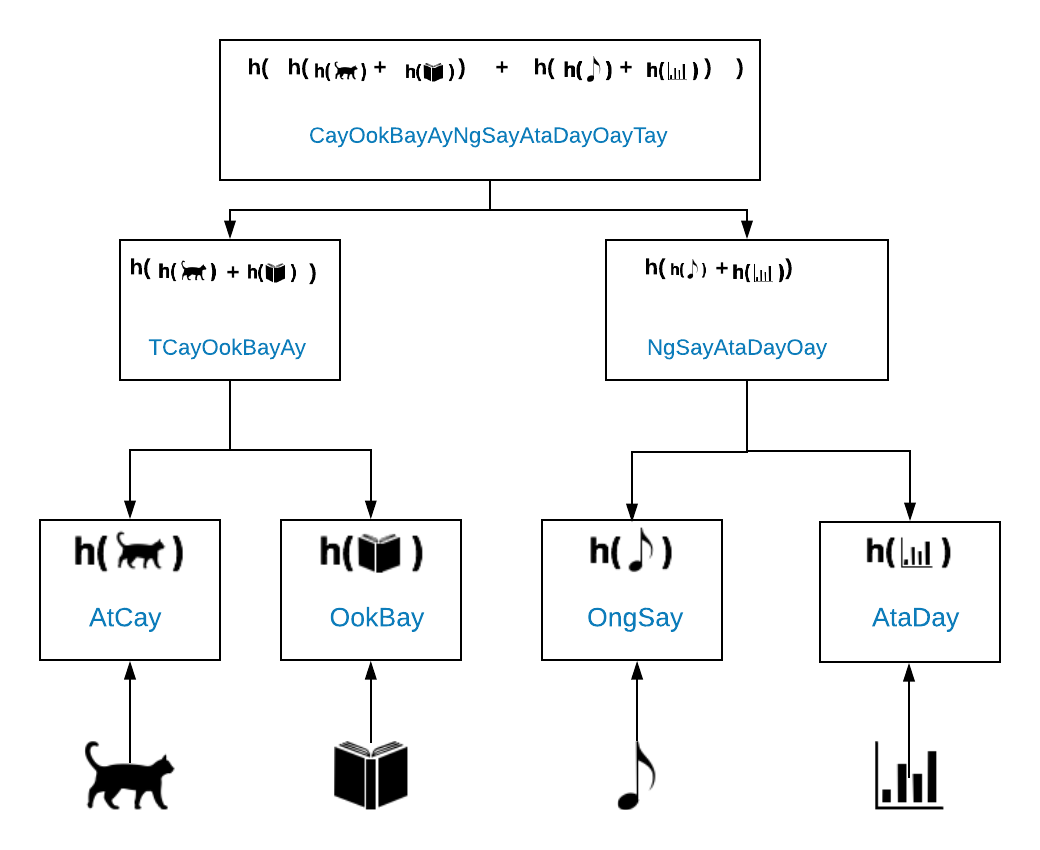
What we’re looking at here is a tree of data. Let’s start at the bottom [of this slide] and assume that you have on your computer four objects: a picture of a cat, a pdf of a book, an mp3 of your favorite song, and a spreadsheet of some data. And what you want to do is take a backup of your system at that time where you have those four digital files.
The way that a Merkle tree works is that each of the leaves (which is the bottom row in the slide) is associated with a piece of data and that piece of data is encrypted. The contents of each leaf node is the encrypted representation of the data it is storing.
When you as a human look at your computer, you see a picture of a cat, a book, a song, and a graph, but under the hood each of these objects is just data, a series of 0’s and 1’s. A cryptographic hash function is applied to the data and encodes it. In the slide, this function is represented by h(data) followed by the encoded version of the data. So using Pig Latin, “encrypting the cat image” would be represented as h(cat) , encrypting the book would be represented by h(book), etc. etc. And in Pig Latin, those two function calls would output AtCat and OokBay, respectively.
And then the data rolls up the tree. The parent of these two children would take the two encrypted representations (of your cat and your book) and put them together to encrypt, creating a new encryption that represents a specific point in time. As you move up the tree, you go from four pieces of data to the two parents and then to the root node of the tree. The root node puts together the encrypted parent strings and runs the hashing algorithm, which again is Pig Latin in this example. This then gives you what’s called the Merkle root, and that piece of data is used to encode all of the data in your tree.
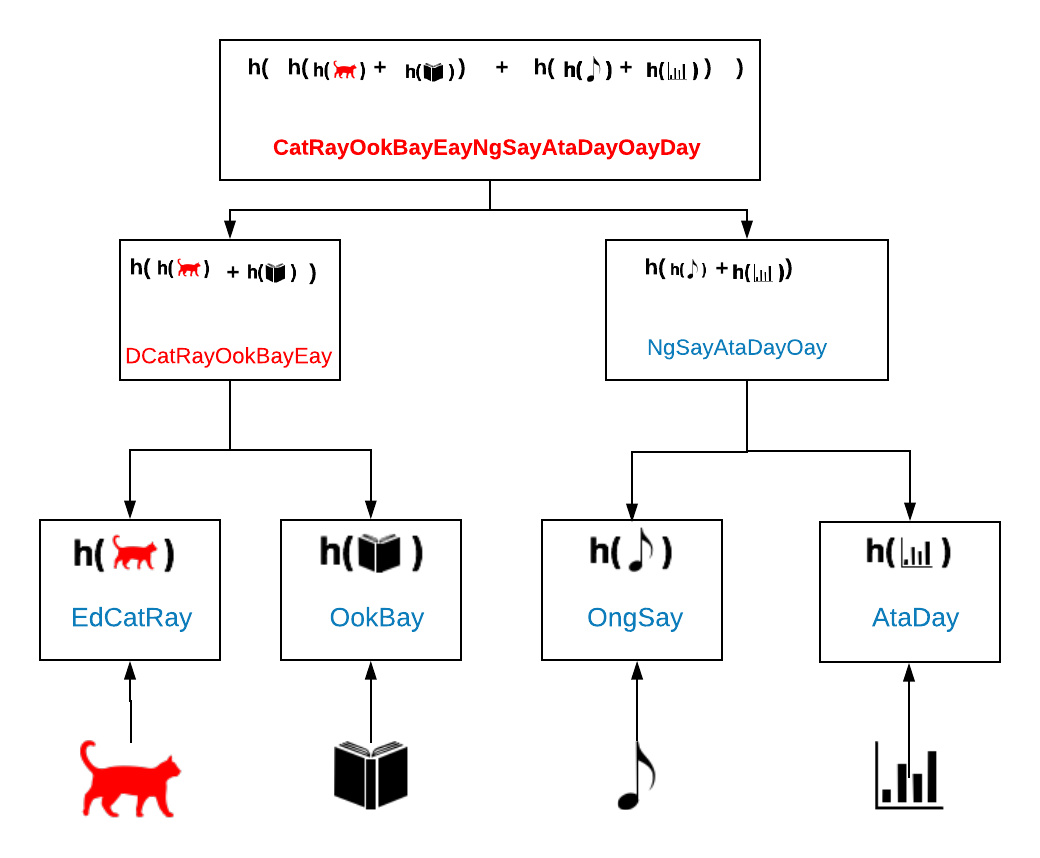
What’s interesting about this structure is if you change any piece of data, the changes propagate all the way to the top. Let’s say we change our cat to a “red cat.” The Merkle root then changes from the previous example. We can see immediately that changes happened in the data-set and that the data is not the same.
In the context of version control of the distributed web, a change might simply mean that you made an update and you have a new version of your cat file. In the context of the blockchain, it could be a sign that someone has tampered with the blocks. A transaction that was said to have happened might have been been tampered with, and then miners can know to ignore that transaction and leave it aside.
When you’re looking at this data structure from a security practise, it’s tamper-proof. When you’re looking at it from a content practise, it’s very specific version-control.
Here is a writeup with slides of what I’ve just spoken about.
Merkle uses an encryption algorithm called SHA-256 which is called a one way encryption algorithm. This means its very easy when you take an input to get the hash key that it encrypts to, but you can’t go backwards, i.e. you can’t take the encrypted string and then get the cat photo. That’s why it’s so secure. It’s never yet been cracked.
However with Pig Latin as our encryption algorithm, it’s easy to go backwards because you know what it is, from “cat” to “atCay.” Also, with Pig Latin everytime you add more content, your “encrypted” string gets bigger and bigger. So using Pig Latin, the “encrypted” representation of the data would be bigger than the actual data itself. Whereas with the SHA-256, every encryption is 64 bits. So if you can have a file that’s extremely long or very short and it’s always going to be represented as a string that’s 64 bits.

Taeyoon: I asked my colleague Rishab to tell us a little bit about his research and what we can learn from Tor.

Rishab Nithyanand
Tor is a very interesting idea because it’s sort of an overlay network, an attempt to implement a distributed system on top of a decentralized internet. Since Tor has been around now for about 15 years, we can learn from it all the problems you’re going to face when trying to build a distributed system on top of an established power structure. I want to talk about some of the problems that Tor has had, as we may face these things as issues in p2p systems later on.
Originally, Tor was built for anonymous communication. Now Tor has been repurposed by a lot of other parts of the world to allow people to circumvent censorship. Another thing about Tor is that it’s volunteer operated. One of the challenges it faces is the difficulty for volunteers to run relays which distribute the internet routing infrastructure that is already in place. The easiest way for people to do this is to rely on cloud services like Amazon and Google. This is because the way the traditional internet is set up makes it difficult to run routing infrastructures in our homes. Yet even if we were able to do this, Comcast, Verizon, and all of the other ISP(Internet Service Providers)’s would have problems with it. So, this is one way in which the traditional power structures are getting in the way of a distributed system. If you do do it on Amazon or Google, you’re then violating their terms of service and you’re going to get kicked out. You cannot run certain types of infrastructures that are required for Tor on these services.
But a good thing that we find with Tor is that you end up with a lot of nice allies. There are a lot of ISP’s which have come out that make it really cheap and easy for users to run Tor infrastructure on their services. When we’re talking about censorship circumvention, there’s this new idea called decoy routing. It works on the idea that there are a lot of good allies and ISP’s around the world that want people from repressed and oppressed regions to have complete access to the internet. Perhaps completely unexpected, AT&T is a potential ally that wants people from Iran to be able to access the internet uncensored or unfiltered. With decoy routing, an ISP will establish a decoy channel for a user in Iran, so what it looks like to people on the outside and to the Iranian regime is that the user is using the AT&T infrastructure, autonomous system or network to access a site which isn’t cenesored, like amazon.com. In reality, the user and the ISP are winking at each other, saying, “We’ll pretend we’re going to amazon.com but we have a little secret in our communication stream which will make it look like I’m going to amazon.com but really I want to go to this news website.” Decoy routing establishes this “wink” in the communication stream between an ISP like AT&T and a user in Iran.
Taeyoon: I think the notion of trust comes into the spotlight here again, thinking about how can you can trust the anonymous systems. Then we begin considering how to redefine trust in a way where it’s beneficial for us to build stronger distributed responsibilities.
Rishab: With systems like the blockchain and Tor, they’ve been built to withstand a certain amount of bad behavior. I think distributed systems can be built to do that as well. The main issues and the main sources of attacks and vulnerabilities for Tor is that there are powerful entities that do not want distributed system to succeed. Correlation attacks come from ISP’s that are at either end of a Tor connection and can perform a traffic analysis to figure out who’s going where. The attacks are coming from powerful entities that exist on the centralized web that do not want the distributed web to succeed. We will have to figure out how to work with these things to make the distributed web a real thing.
Taeyoon: So the last part of the workshop is a question of how can we visualize, enact, perform and become the network of care. Before we perform this together, I wanted to ask if anyone from SFPC had anything to add or share?

Nabil Hassein
I think a lot about the connections between technology and imperialism. I read a lot of mainstream press stuff and I mostly hate it but I keep reading it, because it does have an influence and I try and understand it. In it there’s a lot of orientalist fear-mongering, stuff around the nature of “China is doing something.” Now some of it might actually be bad, but I definitely see the US government as the biggest problem in the world. It’s now been 15 years since the invasion of Iraq and the war is still ongoing there. So when I hear things like, “Oh the Iranian regime is doing something that’s so bad” I feel very skeptical of it and I wonder what’s the purpose and whether it’s supporting basically more war mongering. People still speak of the Iraq War as if it was a mistake and not a deliberate act, when it fact it was completely deliberate and planned. I think we need to have this context in mind when we think about the efforts of the Chinese government, for example, to basically have independent control over their own computing infrastructure rather than be perpetually reliant on the US government, which originally funded the internet and Tor and many of the other projects that people rely on.
So when I think about distributed and decentralized networks, I think about how can we actually have a radical diversity, where instead of everyone being constantly reliant on one single type of computing infrastructure or centralized provider, it becomes a question of what it might actually look like for many different nations and subgroups other than nations– whether black people or queer folks, disabled people– anyone with their own needs that aren’t being served by US imperialism and capitalism. These systems were not built for us and I don’t believe can be reformed for us, so I wonder what could radical diversity look like, and how we, as technologists, can build that.
Taeyoon: So we’re going to try to visualize, enact, perform, and become the network of care, and to do that we are going to first visualize the internet as it stands today. And we are going to try to perform the distributed web of care.






Read a blog by Sarah Gray.
Special thanks
Rhizome, The New Museum, Joe Hand and Danielle Robinson of the DAT project, Tara Vancil of the Beaker, Sean Dockray, Sam Hart, Alexander R. Galloway, Agnes Pyrchla, Nitcha Tothong, Ailadi, Nabil Hassein, Sam Hart, Mindy Seu, Sarah Gray, Callil Capuozzo, Kelly Monson, Michael Connor, Rishab Nithyanandm and the workshop participants.
Photo: Alex Wagner, Lauren Studebaker
Transcription and editing: Shira Feldman
Editing: Emilly Miller, Livia Huang
Support
Distributed Web of Care is an independent, self funded initiative. We are actively searching for supporters. If you’d like to make donation, or hire Taeyoon Choi and the collaborators to lead a workshop, please contact studio@taeyoonchoi.com.

Distributed Web of Care is an initiative to code to care and code carefully.
The project imagines the future of the internet and consider what care means for a technologically-oriented future. The project focuses on personhood in relation to accessibility, identity, and the environment, with the intention of creating a distributed future that’s built with trust and care, where diverse communities are prioritized and supported.
The project is composed of collaborations, educational resources, skillshares, an editorial platform, and performance. Announcements and documentation are hosted on this site, as well as essays by select artists, technologists, and activists.
-
Jun 30, 2024
에콜로지컬 퓨쳐스
-
Jun 30, 2024
Ecological Futures
-
Nov 26, 2022
P2P Residency Berlin
-
Jan 4, 2022
garden.local
-
Jun 7, 2020
Community Over Commodity
-
Mar 18, 2020
Oddkins
-
Oct 10, 2019
New Merchandise
-
Aug 10, 2019
Announcing Decentralized Networks Workshop
-
May 24, 2019
On Stewardship
-
May 23, 2019
Movement Scores
-
May 4, 2019
Who Owns the Stars: The Trouble with Urbit
-
May 1, 2019
Announcing WYFY School with BUFU
-
Mar 5, 2019
Announcing Lecture Performance at the Whitney Museum
-
Feb 25, 2019
Announcing Call for Deaf or Disabled Stewards
-
Feb 7, 2019
Making Space in Online Archives
-
Jan 29, 2019
Accessibility Dreams
-
Jan 28, 2019
Creative Self Publishing
-
Jan 11, 2019
Racial Justice in the Distributed Web
-
Dec 29, 2018
Announcing LACA Residency
-
Dec 28, 2018
Announcing DWC at Code Societies
-
Dec 21, 2018
Building a Museum 353 Years in the Future
-
Sep 11, 2018
Finding Intimacy within Black Feminist Criticism
-
Jul 26, 2018
still stuck with words
-
Jul 26, 2018
Distributed Dance Floor
-
Jun 27, 2018
Announcing Skillshares: Peers in Practice
-
Jun 27, 2018
Announcing the Distributed Web of Care Party
-
Jun 27, 2018
Communities and New Infrastructures
-
Jun 27, 2018
New Gardens
-
May 20, 2018
Announcing Summer 2018 Fellows
-
Apr 28, 2018
DWC Merchandise: Care Shirt & Hoodie
-
Apr 27, 2018
Announcing Artists in Residence at Ace Hotel New York
-
Apr 18, 2018
Documentation: Ethics and Archiving the Web
-
Apr 18, 2018
Call for Fellows and Stewards
-
Apr 17, 2018
Code of Conduct
-
Mar 18, 2018
About
-
Distributed Web of Care